

データ分析や可視化は、Pythonを学ぶ初心者にとっても魅力的な技術です。
本記事では、PythonのライブラリであるMatplotlibを使って、簡単なコードだけでデータをグラフに出力する方法をご紹介します。
プログラミング経験が少ない方でも、わかりやすい手順でデータの可視化ができるように解説していきます。
当記事では最低限の解説のみ記していますが、読むのが面倒な方は記事の最後には、データを簡単にグラフで可視化するためのコードがまとめてあります。これをコピーして実行するだけで、Pythonでのデータ可視化を試すことができます。手軽に実践してみたい方はまとめまで飛んでください。
Pythonの優位性
Pythonのデータ可視化は、エクセルに比べて柔軟性があり、特にデータ量が多く複雑な場面で優れています。
また、大規模なデータセットにも対応し、効率的な処理を実現できると同時に、処理の自動化と再現性を確保することができます。
さらに、MatplotlibをやSeabornなどのライブラリを効果的に用いることにより、カスタマイズ性と美しいデザインを実現できます。
データの複雑な分析や可視化も可能で、範囲選択やスクロールの煩雑さから解放されます。
Pythonの強みは、無料で提供される優れたツールを用いて、データの視覚的な表現を高度な柔軟性と効率で実現できる点にあります。
データ準備
Google Colab環境を使用する場合
Google Drive上にpythonフォルダを作成し、pythonフォルダ内にplot_data.ipynbファイルを作成してください。
はじめにGoogle Driveをマウントします。
from google.colab import drive
drive.mount('/content/drive')続いてテストデータ作成用のコードを記述します。
手元にデータが存在する場合は、次の手順は不要です。上のコードをコピペしたら「グラフ作成」に進んでください。
手元にデータが無い場合は以下のコードでテストデータを生成してください。
プロットするテストデータを作成しているだけなのでコードを理解する必要は全くありません。
import random
import pandas as pd
DIR = "drive/My Drive/python/"
# 方程式のパラメータ
m = 0.5
q = 2
# データの数
data_num = 100
# ノイズの範囲
noise_range = 0.5
data = []
for x in range(data_num):
y = m * x + q + random.uniform(-noise_range, noise_range)
data.append((x, y))
# データをDataFrameに変換
df = pd.DataFrame(data)
# CSVファイルにデータを書き込む
filename = f"{DIR}/test_data.csv"
df.to_csv(filename, index=False, header = False)
print(f"データが {filename} に出力されました。")
コードを実行するとテストデータが出力されます。
グラフ作成
コードで作成したデータを使用する場合
import matplotlib.pyplot as plt
# CSVファイルからデータを読み込む
df = pd.read_csv(filename, header=None)
# データをプロット
plt.figure(figsize=(8, 6))
plt.scatter(df[0], df[1], color='k')
plt.show()手元のデータを使用する場合
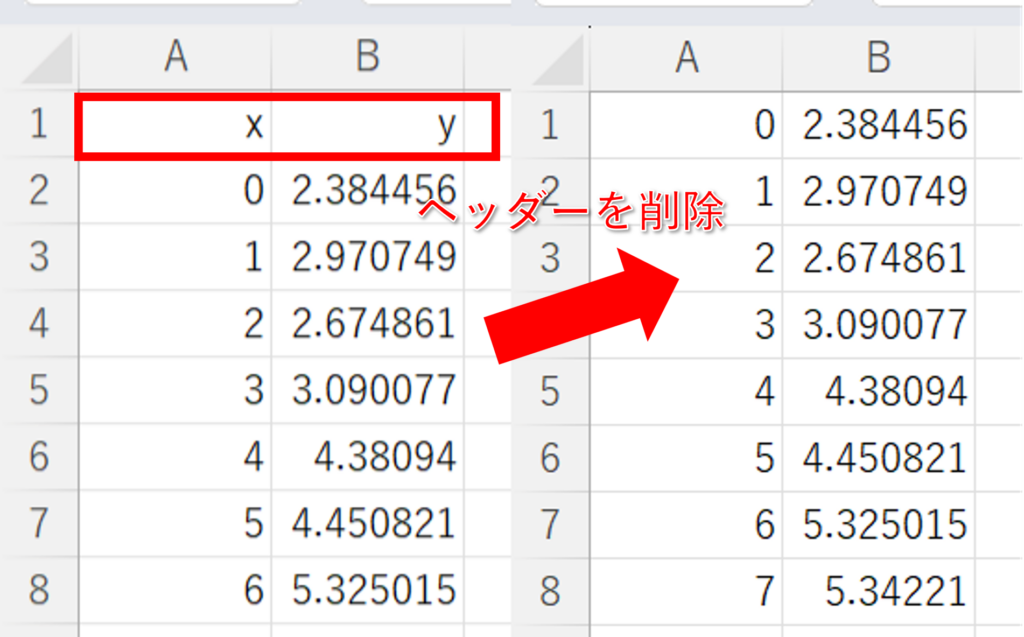
以下のコードではcsvファイルにはヘッダーが無く、左上(A1)に最初のデータが格納されていることを想定しています。
また、Aカラムがx軸、Bカラムがy軸にプロットされます。
ヘッダーやメモなど、データ以外の文字が含まれる場合には別途処理が必要です。
よくわからない人は元データをコピーして左上(A1)に最初のデータが格納されるようにcsvファイルを修正してください。
Pandasを少しだけ勉強すればこのような手作業からも解放されます。
filenameの”で囲まれた部分は手元のファイル名にしてください。
import matplotlib.pyplot as plt
DIR = "drive/My Drive/python/"
filename = DIR + "data.csv"
# CSVファイルからデータを読み込む
df = pd.read_csv(filename, header=None)
# データをプロット
plt.figure(figsize=(8, 6))
plt.scatter(df[0], df[1], color='k')
plt.show()グラフ設定
import numpy as np
a,b=np.polyfit(df[0],df[1],1)
# データをプロット
plt.figure(figsize=(8, 6))
plt.scatter(df[0], df[1], color='k', label="Data")
plt.plot(df[0], a*df[0]+b, color='r', label="Linear Fit")
plt.legend()
plt.xlabel("x")
plt.ylabel("y")
plt.title("Title")
plt.grid(True)
figname = f"{DIR}/plot_test.png"
plt.savefig(figname)
plt.show()figure 関数を呼び出して新しい図を作成する。
(幅, 高さ)と記述することで任意のサイズの図を作成します。
plt.figure(figsize=(8, 6))データを可視化する
プロット関数を使用してデータを可視化します。
plt.scatterは散布図、plt.plotは折れ線グラフを作成します。
引数を与えると色や凡例を指定することができます。
plt.scatter(df[0], df[1], color='k', label="Data")
plt.plot(df[0], a*df[0]+b, color='r', label="Linear Fit")
plt.legend()凡例はlabel=”legend”のように指定します。指定後にplt.legend()を呼び出すと凡例が表示されます。日本語を表示するためには対応しているフォントを使用する必要があります。
色はcolor=’r’やcolor=’red’のように指定します。指定できる色はList of named colorsで確認することができます。
| 色(日本語) | 1文字 | 色(英語) |
| 青 | b | blue |
| 緑 | g | orange |
| 赤 | r | green |
| シアン | c | red |
| 紫 | m | purple |
| 黄 | y | yellow |
| 黒 | k | black |
| 白 | w | white |
xy軸ラベルとタイトルを指定します。
凡例と同様に日本語を表示するためには対応しているフォントを使用する必要があります。
plt.xlabel("x")
plt.ylabel("y")
plt.title("Title")グリッド線を表示
plt.grid(True)グラフを保存
figname = f"{DIR}/plot_test.png"
plt.savefig(figname)最後に、プロットしたグラフをウィンドウに表示するためにplt.show()を使用します。
plt.show()まとめ
最後に当記事で解説したコードをまとめて表示します。
見やすさのために1つのセルに全てのコードをまとめていますが、コードセルは適宜分けてください。(もちろん1つのセルにまとめてコピペしても動きます。)
解説を読み飛ばしてまとめにたどり着いた方は、Google Colaboratoryで以下のコードを動かしてみてください。
手元に可視化するデータが無い場合
Google DriveのMy Driveにpythonフォルダを作成して、その中にplot_data.ipynbを配置してください。
from google.colab import drive
import random
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Google Driveをマウント
drive.mount('/content/drive')
# パス定義
DIR = "drive/My Drive/python/"
# 方程式のパラメータ
m = 0.5
q = 2
# データの数
data_num = 100
# ノイズの範囲
noise_range = 0.5
data = []
for x in range(data_num):
y = m * x + q + random.uniform(-noise_range, noise_range)
data.append((x, y))
# データをDataFrameに変換
df = pd.DataFrame(data)
# CSVファイルにデータを書き込む
filename = f"{DIR}/test_data.csv"
df.to_csv(filename, index=False, header = False)
print(f"テストデータが {filename} に出力されました。")
# 線形近似
a,b=np.polyfit(df[0],df[1],1)
# データをプロット
plt.figure(figsize=(8, 6))
plt.scatter(df[0], df[1], color='k', label="Data")
plt.plot(df[0], a*df[0]+b, color='r', label="Linear Fit")
plt.legend()
plt.xlabel("x")
plt.ylabel("y")
plt.title("Title")
plt.grid(True)
figname = f"{DIR}/plot_test.png"
plt.savefig(figname)
plt.show()手元のデータを使用する場合
Google DriveのMy Driveにpythonフォルダを作成して、その中に可視化したいデータのファイルとplot_data.ipynbを配置してください。
以下のコードをコピペした後、filename = DIR + “data.csv”の(”)で囲まれた部分を使用するデータファイル名に置き換えてください。
from google.colab import drive
import random
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Google Driveをマウント
drive.mount('/content/drive')
# パス定義
DIR = "drive/My Drive/python/"
filename = DIR + "data.csv"
# CSVファイルからデータを読み込む
df = pd.read_csv(filename, header=None)
# 線形近似
a,b=np.polyfit(df[0],df[1],1)
# データをプロット
plt.figure(figsize=(8, 6))
plt.scatter(df[0], df[1], color='k', label="Data")
plt.plot(df[0], a*df[0]+b, color='r', label="Linear Fit")
plt.legend()
plt.xlabel("x")
plt.ylabel("y")
plt.title("Title")
plt.grid(True)
figname = f"{DIR}/plot_test.png"
plt.savefig(figname)
plt.show()手元のファイルがエクセル形式である場合はデータを読み込む行を以下のように変更してください。
df = pd.read_excel(filename, header=None)
