
Pythonでデータを読み込み、可視化する方法は様々あります。
当記事では、時系列データのデータフレームを例にして、以下3つの手法を比較します。
matplotlibを使う方法df.plot()を使う方法plotlyを使う方法
データの準備
はじめに、可視化するデータを用意します。
データのダウンロード
気象庁から東京の気象データをダウンロードします。
今回は日別に
- 日平均気温
- 日最高気温
- 日最低気温
- 日平均相対湿度
のデータを1年分(2020年)取得しました。
ダウンロードした「data.csv」ファイルを適切なパスに配置します。
今回はソースコードと同階層に「data」フォルダを作成し、「data」フォルダ内に「data.csv」を配置します。
pandasでデータを整理
最初に、データ整理のためのコードをまとめて記述します。
解説が不要な方は以下の解説をとばしてください。
import pandas as pd
import matplotlib.pyplot as plt
import plotly.express as px
import japanize_matplotlib
BASE_DIR = "."
INPUT_DIR = f"{BASE_DIR}/data"
filename = f"{INPUT_DIR}/data.csv"
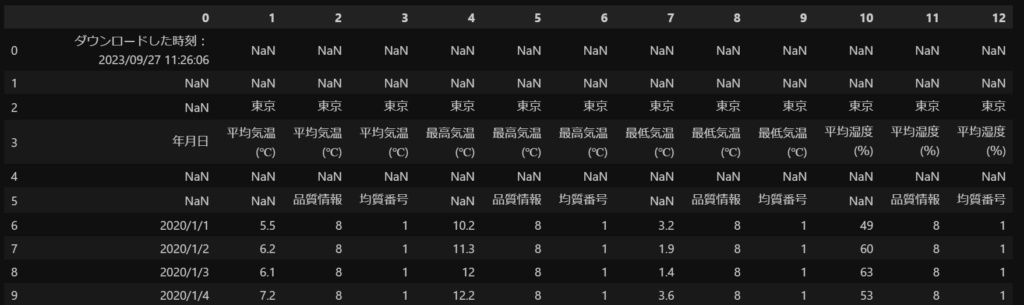
df = pd.read_csv(filename, encoding='shift-jis', header=None)
df = df.iloc[:,[0,1,4,7,10]]
df.columns = df.iloc[3].tolist()
df.set_index(df.columns[0], inplace=True)
df = df.iloc[6:]
df = df.astype(float)
df.index = pd.to_datetime(df.index)
df['日付'] = df.index.strftime('%m月%d日')
df['year'] = df.index.year出力
まず、必要なライブラリをインポートします。
import pandas as pd
import matplotlib.pyplot as plt
import plotly.express as px
import japanize_matplotlib次に、パスを定義します。
BASE_DIR = "."
INPUT_DIR = f"{BASE_DIR}/data"
filename = f"{INPUT_DIR}/data.csv"csvファイルをdf型で読み込みます。
df = pd.read_csv(filename, encoding='shift-jis', header=None)
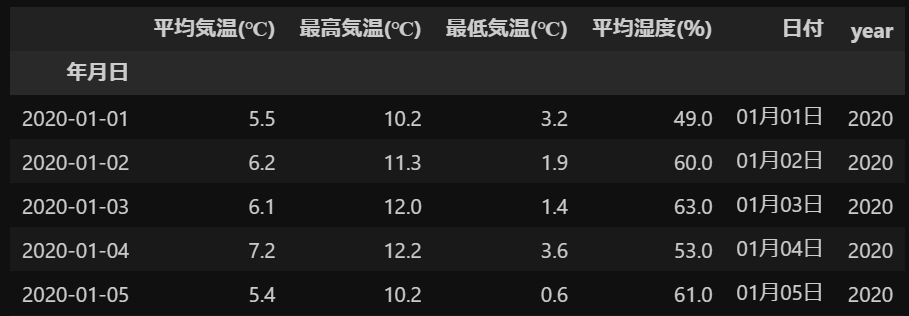
display(df.head(10))出力
今回使用するデータは列は0、1、4、7、10列目で、行は6行目以降に格納されています。
また、列名(columns)として3行目の「年月日」、「平均気温(℃)」、「最高気温(℃)」、「最低気温(℃)」を使用します。
そして、行名(index)には「年月日」の列を割り当てます。
さらに、データを数値型に変換する必要があります。
これらの処理をコードで書くと以下のようになります。
df = df.iloc[:,[0,1,4,7,10]]
df.columns = df.iloc[3].tolist()
df.set_index(df.columns[0], inplace=True)
df = df.iloc[6:]
df = df.astype(float)
display(df)出力
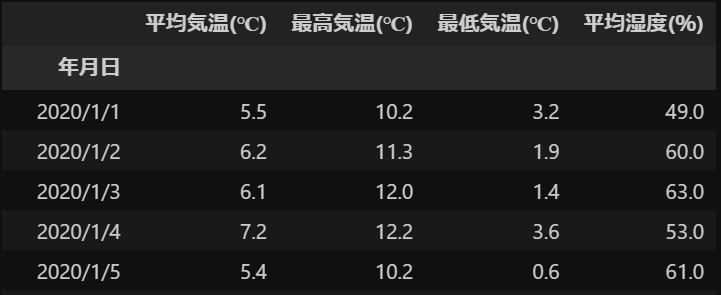
次に行名(index)をdatetime型に変換します。
また、日付を’%m月%d日’の形式で表した「日付」列、年のみを抽出した「yaer」列を追加します。
df.index = pd.to_datetime(df.index)
df['日付'] = df.index.strftime('%m月%d日')
df['year'] = df.index.year
display(df)出力
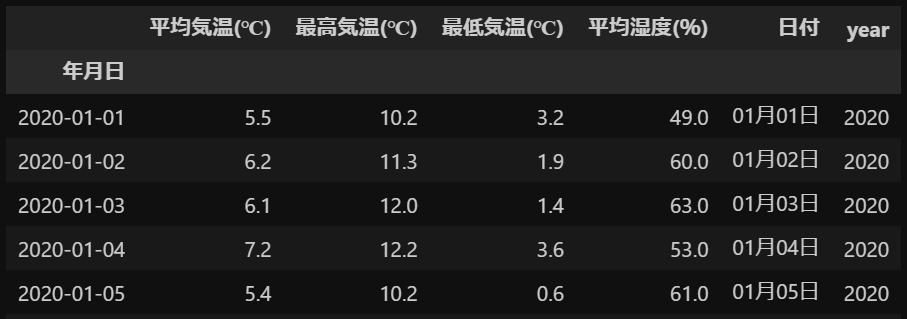
可視化するデータフレームを準備することができました。
データの可視化
シンプルなグラフ
dfという変数に格納されたデータの内、「平均気温(℃)」の推移を可視化してみます。
まずは、df.plot()を使って可視化します。
df.plot(y='平均気温(℃)')
plt.show()出力
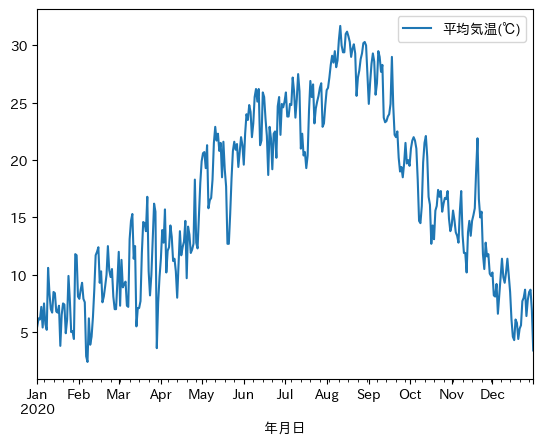
非常にシンプルなコードで分かりやすいです。
可視化したいdfに対してdf.plot()として引数にy=”カラム名”と与えています。
xパラメータを指定していませんが、dfのインデックスが自動でx軸となります。
次に、px(plotly.express)で可視化します。
fig = px.line(df, y='平均気温(℃)')
fig.show()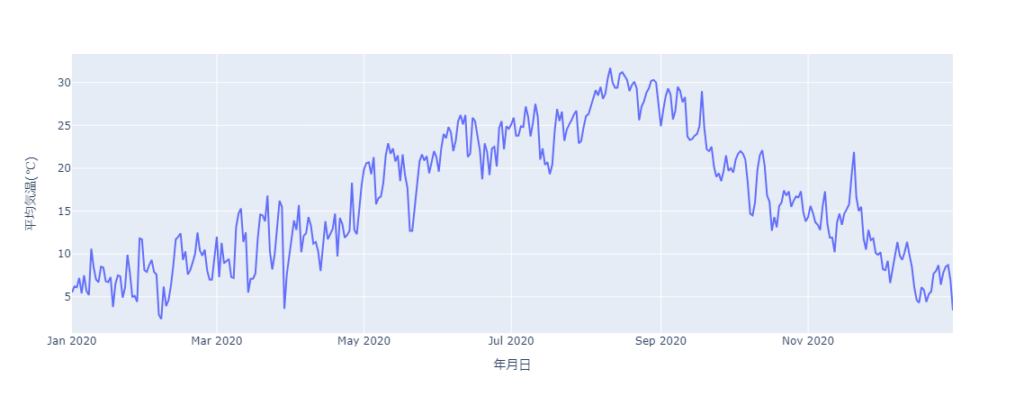
サイズやレイアウトが自動で調節され、x,y軸ラベルも自動で表示してくれます。
続いて同じことをplt(matplotlib.pyplot)で行います。
plt.plot(df['平均気温(℃)'])
plt.show()出力
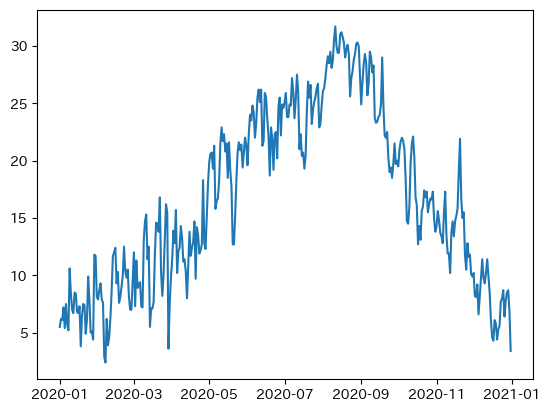
横幅が小さく、目盛が重なっていて見づらいです。
x,y軸ラベルも表示できていません。
pxと同等のグラフを作成するには手動で各種設定を加える必要があります。
plt.figure(figsize=(12, 6))
plt.plot(df['平均気温(℃)'])
plt.xlabel('日付')
plt.ylabel('平均気温(℃)')
plt.grid()
plt.tight_layout()
plt.show()出力

pxでは自動で各種設定が行われますが「update_layout」を用いて手動で指定することもできます。
fig = px.line(df, y='平均気温(℃)')
fig.update_layout(title='気温推移', title_x=0.5, xaxis_title='日付', yaxis_title='気温(℃)')
fig.show()出力
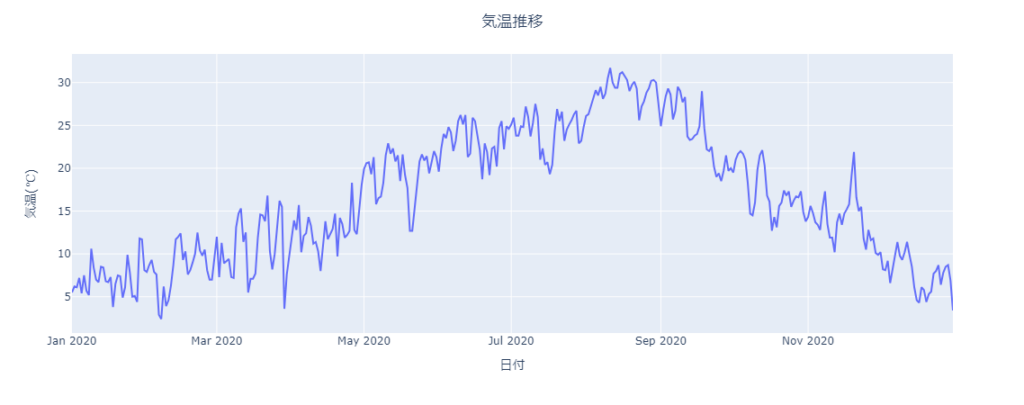
重ねてプロット
平均気温の他に最高気温、最低気温も追加したいとき、df.plot()やpxでは引数yにplotしたいカラム名をリストで渡すだけです。
df.plot(y=['平均気温(℃)','最高気温(℃)','最低気温(℃)'])
plt.show()出力
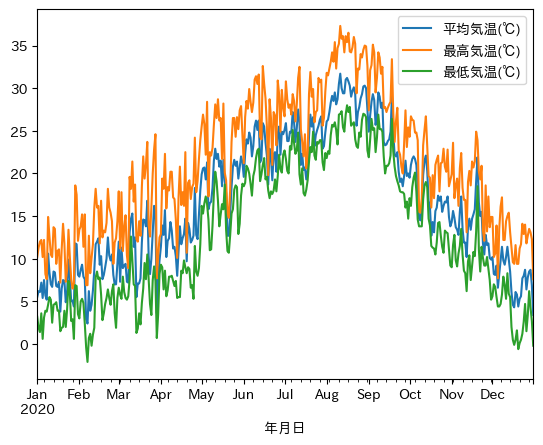
fig = px.line(df, y=['平均気温(℃)', '最高気温(℃)', '最低気温(℃)'])
fig.show()出力
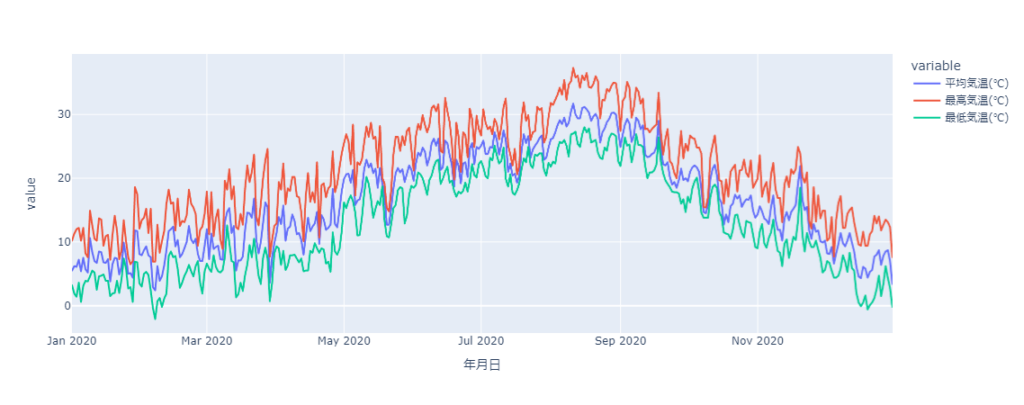
凡例も自動で追加されます。
もちもん手動で設定することもできます。
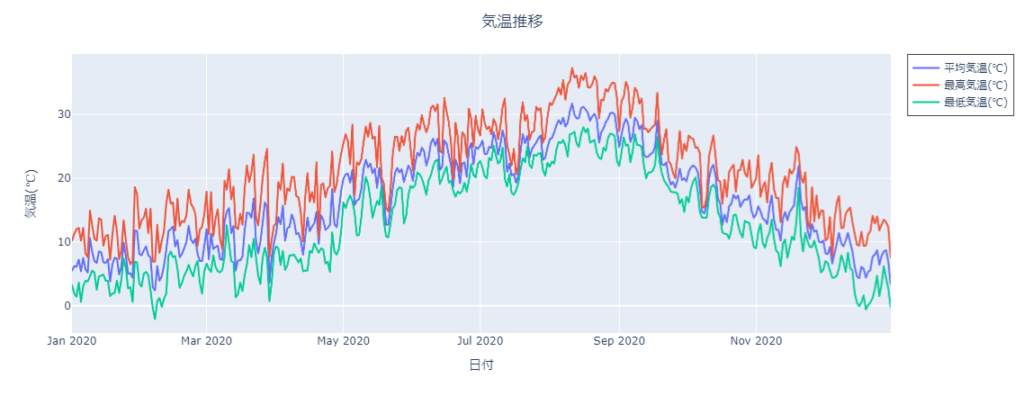
fig = px.line(df, y=['平均気温(℃)', '最高気温(℃)', '最低気温(℃)'])
fig.update_layout(
title='気温推移',
title_x=0.5,
xaxis_title='日付',
yaxis_title='気温(℃)',
legend=dict(
title_text='',
borderwidth=1,
)
)
fig.show()出力
pltでも第2引数に渡す「df[]」の「[]」の中にplotしたいカラム名をリストで渡すことで重ねてプロットすることができます。
plt.plot(df[['平均気温(℃)','最高気温(℃)','最低気温(℃)']])
plt.show()出力

こちらもレイアウトの設定をしていきます。
x,y軸ラベルやタイトルの他に凡例も手動で設定する必要があります。
凡例を表示するにはplt.plotの引数に「label=」を設定した後、plt.legend()を呼び出します。
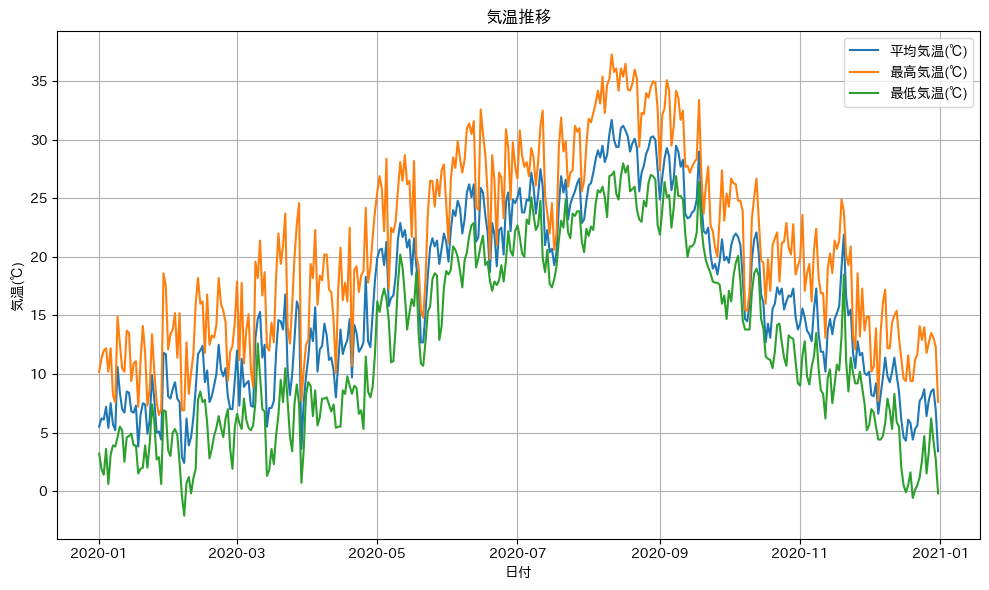
plt.figure(figsize=(10, 6))
plt.plot(df[['平均気温(℃)','最高気温(℃)','最低気温(℃)']], label=['平均気温(℃)','最高気温(℃)','最低気温(℃)'])
plt.title('気温推移')
plt.xlabel('日付')
plt.ylabel('気温(℃)')
plt.legend()
plt.grid(":")
plt.tight_layout()
plt.show()出力
第2軸の追加
第2軸を追加するような複雑なグラフを作成するためにplotlyで必要なモジュールを追加でインポートします。
pltでグラフを作成する場合は不要です。
from plotly.subplots import make_subplots
import plotly.graph_objects as goまずはplotlyで作成します。
fig = make_subplots(specs=[[{"secondary_y": True}]])
fig.add_trace(go.Scatter(x=df.index, y=df["平均気温(℃)"], name="平均気温(℃)"))
fig.add_trace(go.Scatter(x=df.index, y=df["平均湿度(%)"], name="平均湿度(%)", yaxis="y2"))
fig.show()出力

凡例は自動で表示されましたがラベルは表示されませんでした。
手動で設定してみます。
fig = make_subplots(specs=[[{"secondary_y": True}]])
fig.add_trace(go.Scatter(x=df.index, y=df["平均気温(℃)"], name="平均気温(℃)"))
fig.add_trace(go.Scatter(x=df.index, y=df["平均湿度(%)"], name="平均湿度(%)", yaxis="y2"))
fig.update_yaxes(title_text="平均気温(℃)", showgrid=False)
fig.update_yaxes(title_text="平均湿度(%)", showgrid=False, secondary_y=True)
fig.update_yaxes(range=[0, df["平均湿度(%)"].max() * 1.05], secondary_y=True)
fig.update_layout(title="気温と湿度の推移", title_x=0.5)
fig.show()出力
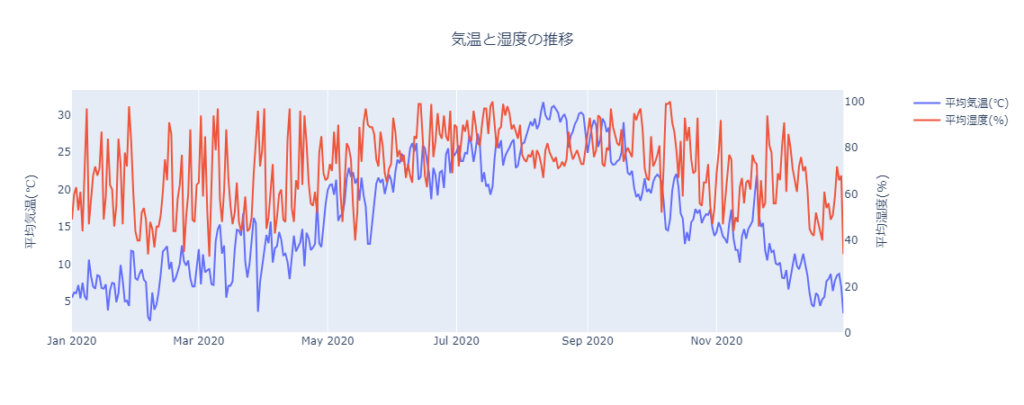
fig.update_yaxesでy軸に関する設定を変更することができます。
fig.update_yaxesでsecondary_y=Trueとすることで第2軸の設定を変更することができます。
次にpltでグラフを作成します。
fig, ax1 = plt.subplots(figsize=(10, 6))
ax1.plot(df["平均気温(℃)"], color="tab:red", label="平均気温(℃)")
ax2 = ax1.twinx()
ax2.plot(df["平均湿度(%)"], color="tab:blue", label="平均湿度(%)")
plt.show()出力
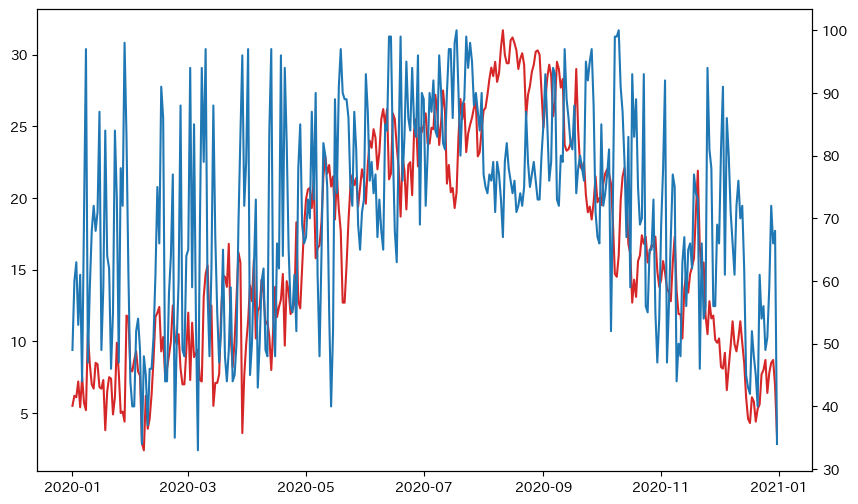
凡例とタイトルを追加し、レイアウトを整えます。
fig, ax1 = plt.subplots(figsize=(10, 6))
ax1.plot(df["平均気温(℃)"], color="tab:red", label="平均気温(℃)")
ax1.set_xlabel("日付")
ax1.set_ylabel("平均気温(℃)")
ax2 = ax1.twinx()
ax2.plot(df["平均湿度(%)"], color="tab:blue", label="平均湿度(%)")
ax2.set_ylabel("平均湿度(%)")
ax1.grid()
lines, labels = ax1.get_legend_handles_labels()
lines2, labels2 = ax2.get_legend_handles_labels()
ax1.legend(lines + lines2, labels + labels2)
plt.title("気温と湿度の推移")
plt.tight_layout()
plt.show()出力
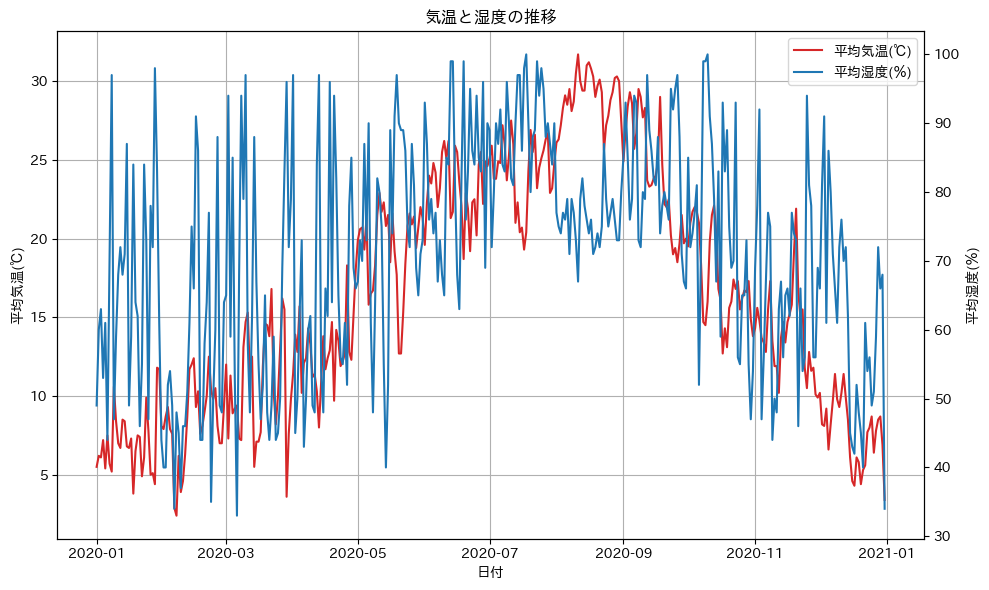
まとめ
当記事で扱った3つの手法はそれぞれに利点欠点があります。
以下のように使い分けると良いでしょう。
- 動的な可視化が必要な場合は、Plotlyを活用
- 細かい設定が必要な場合は、Matplotlibを使用
- 素早く可視化したい場合は、df.plotメソッドを利用

